Abstract
State-of-the-art methods for self-supervised learning (SSL) build representations by maximizing the similarity
between different transformed "views" of a sample. Without sufficient diversity in the transformations used to
create views, however, it can be difficult to overcome nuisance variables in the data and build rich
representations. This motivates the use of the dataset itself to find similar, yet distinct, samples to serve as
views for one another.
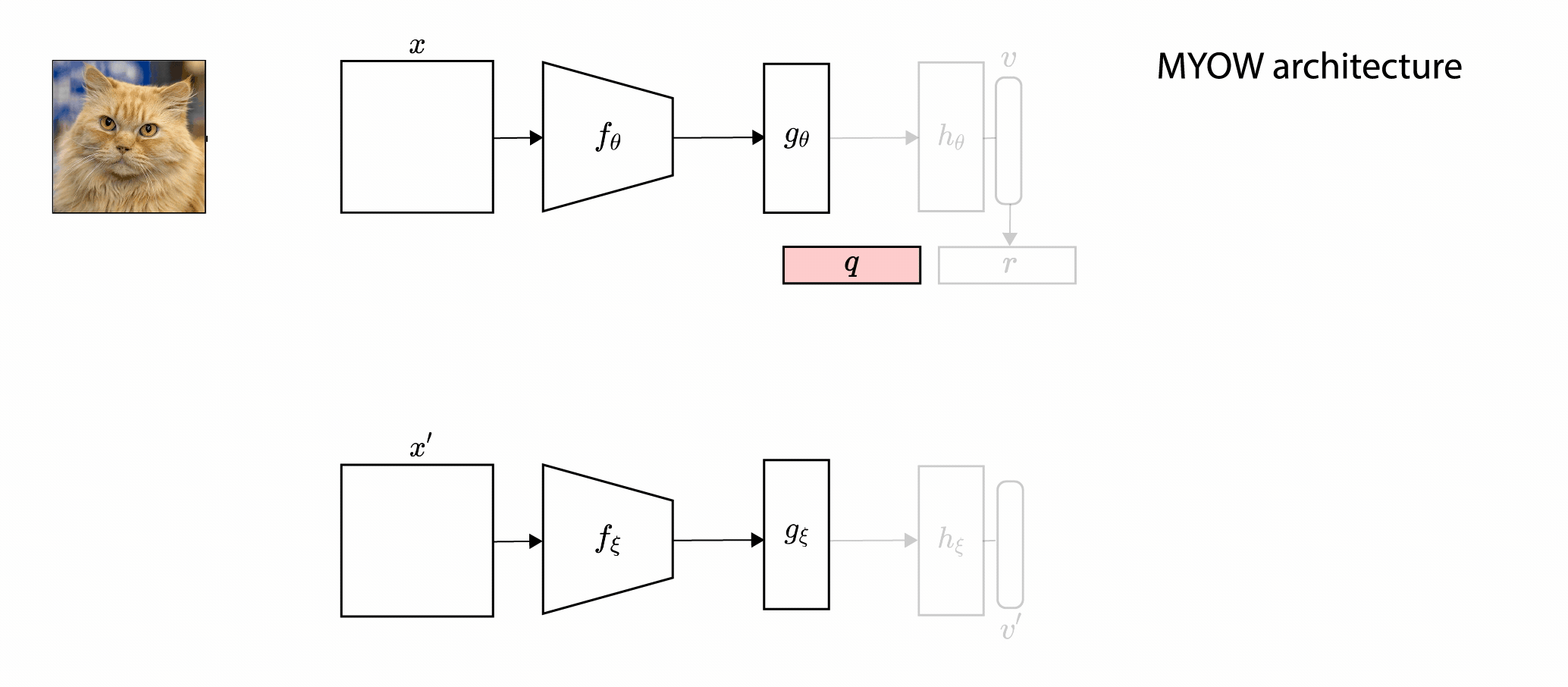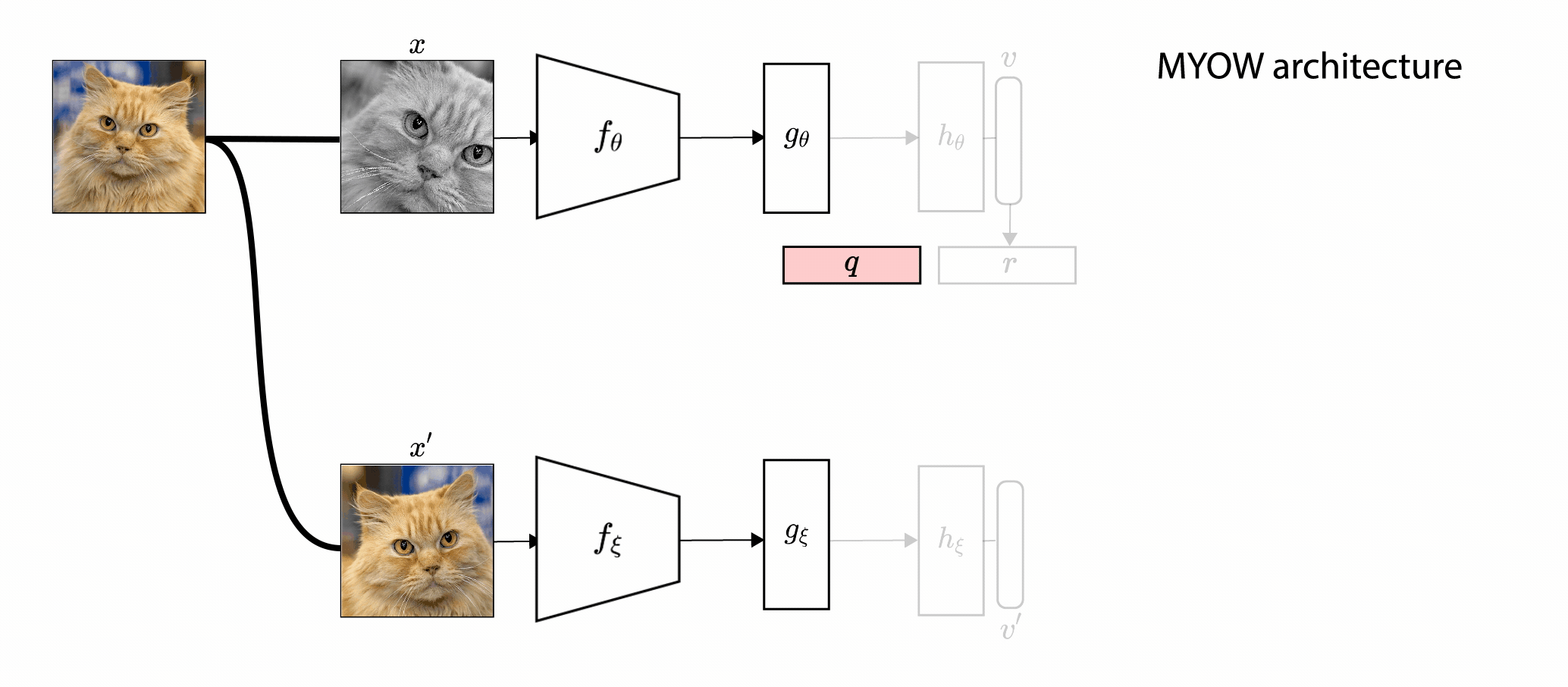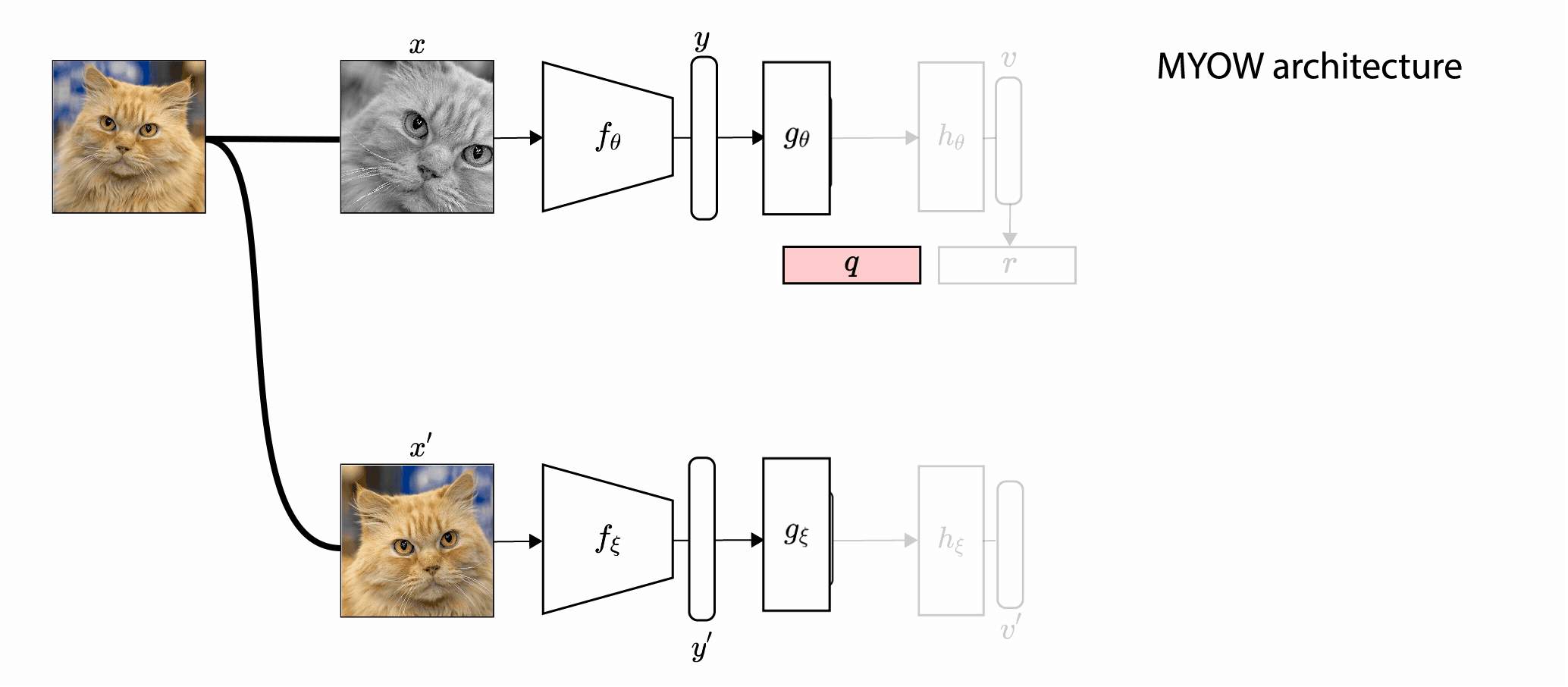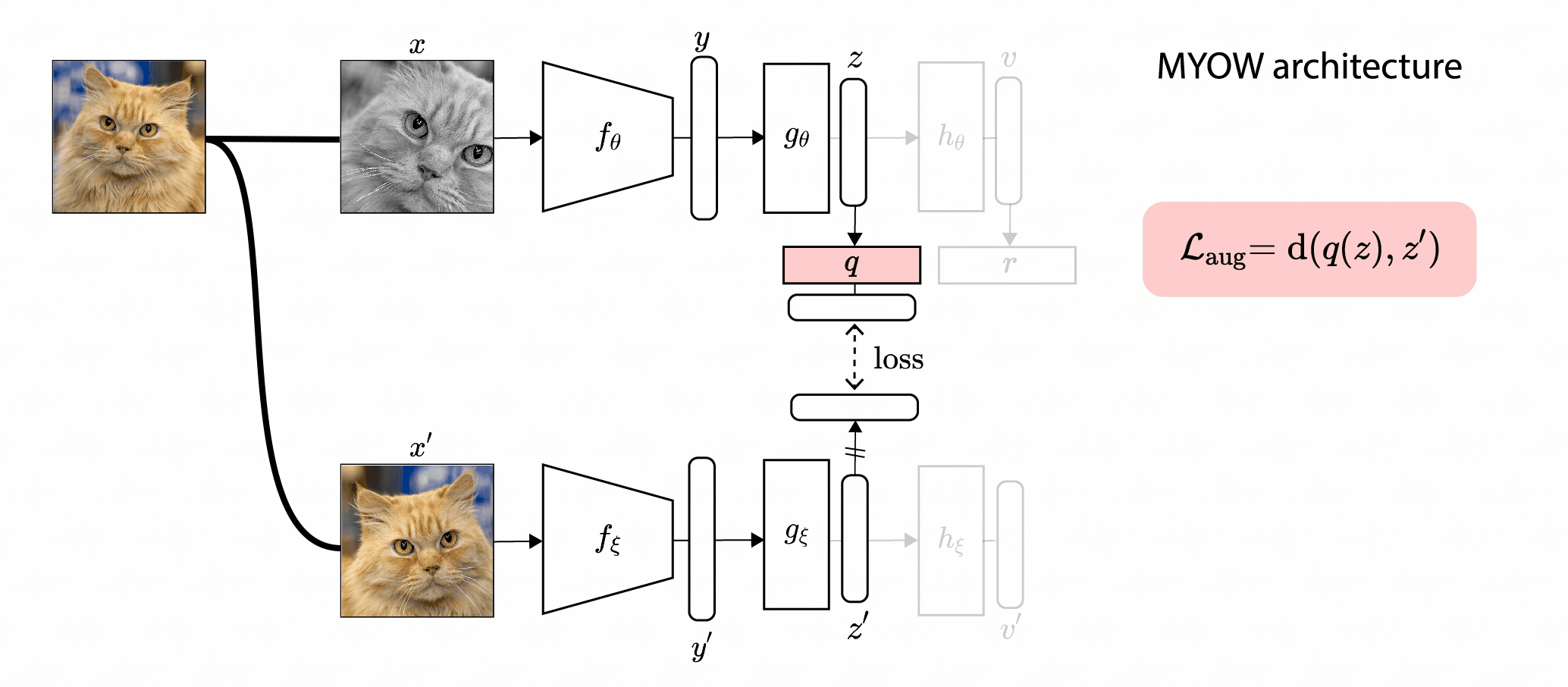
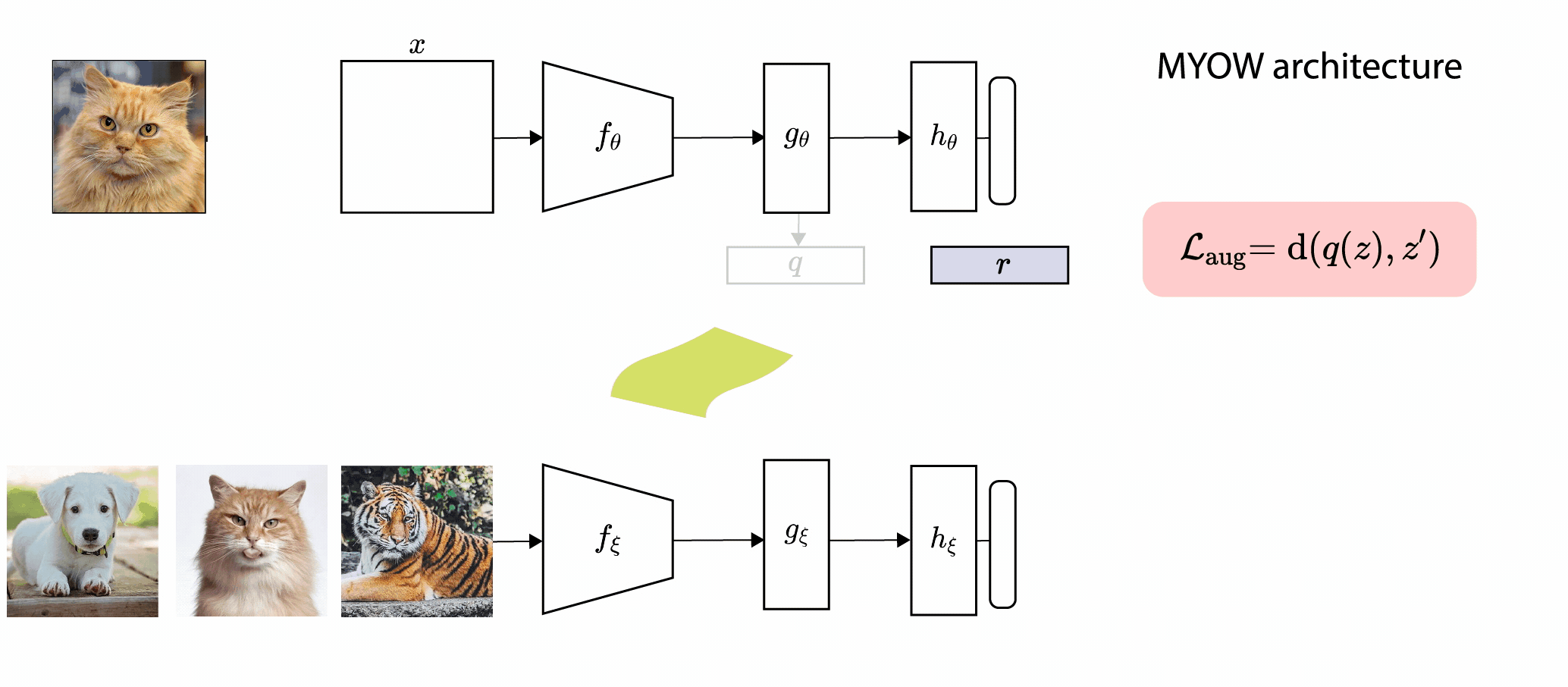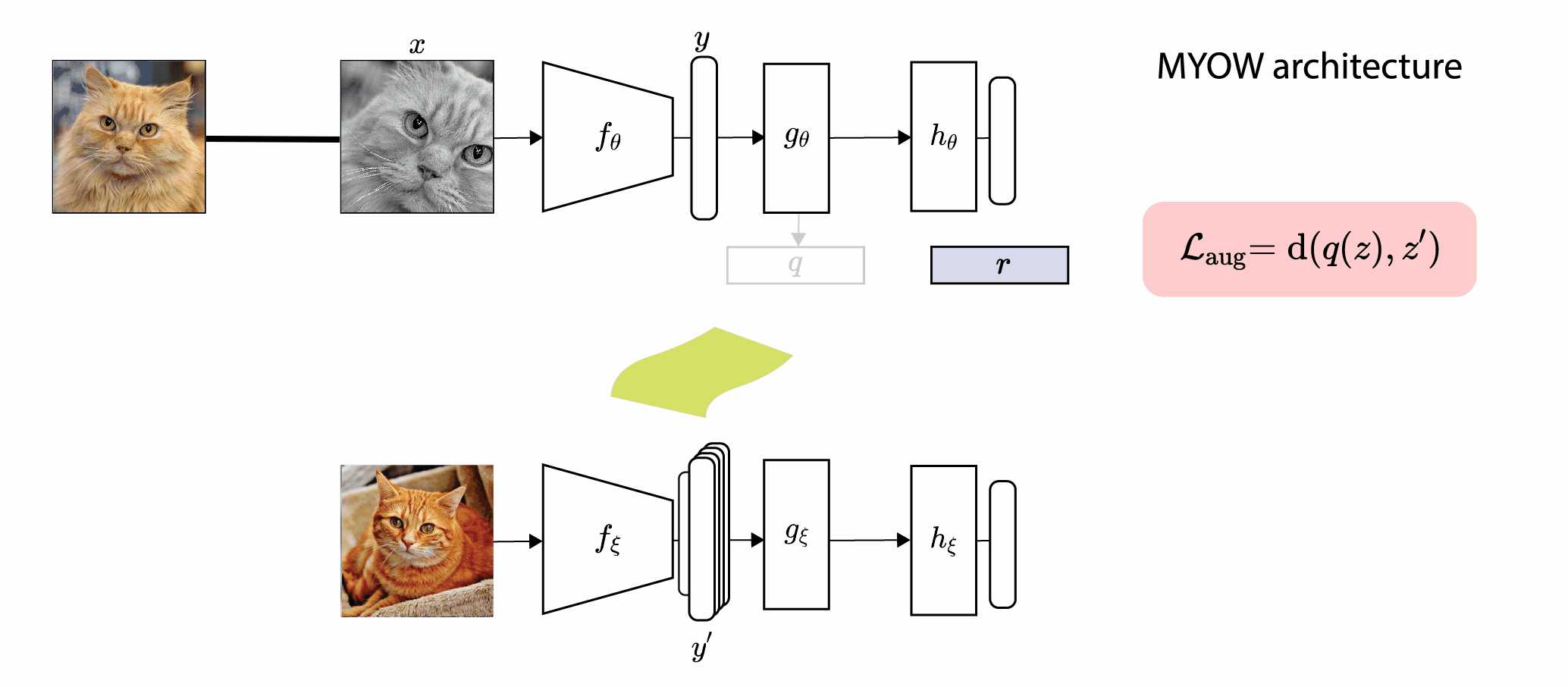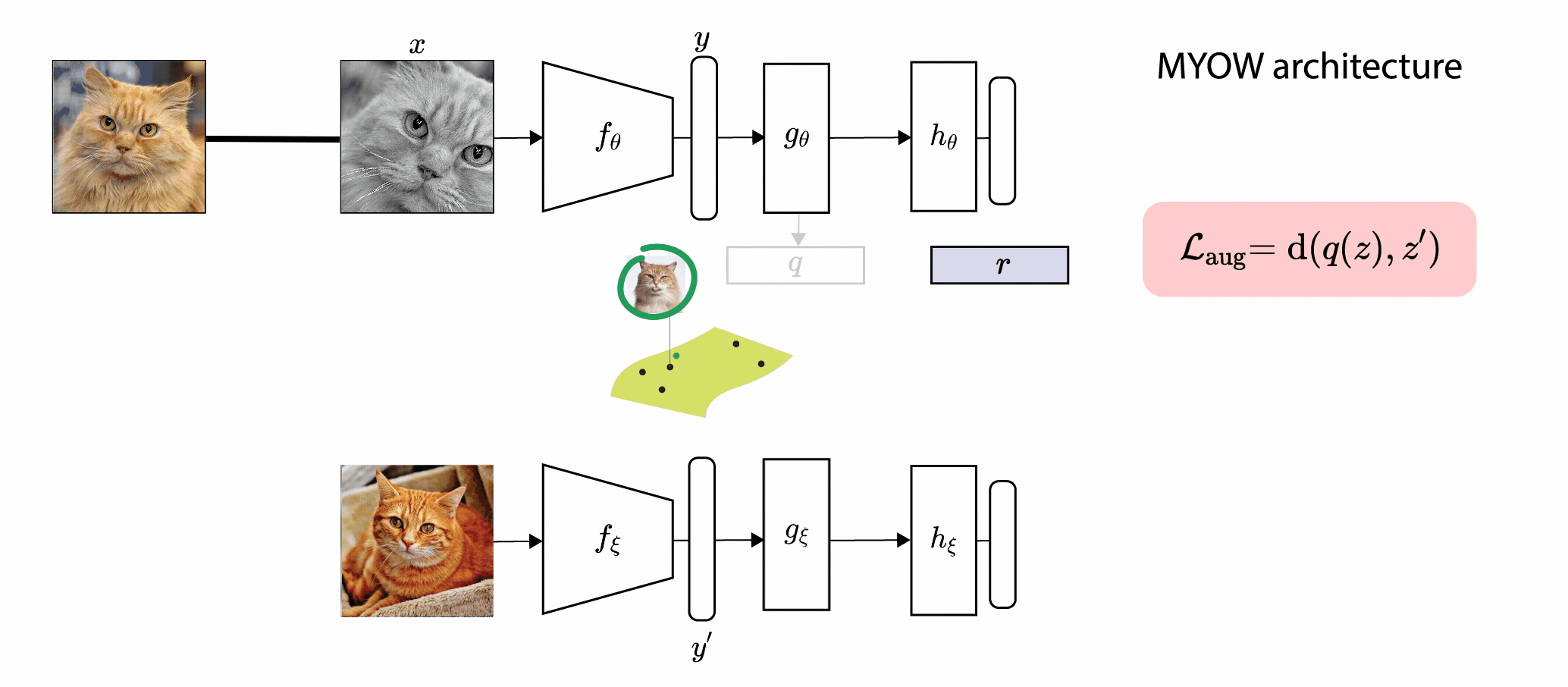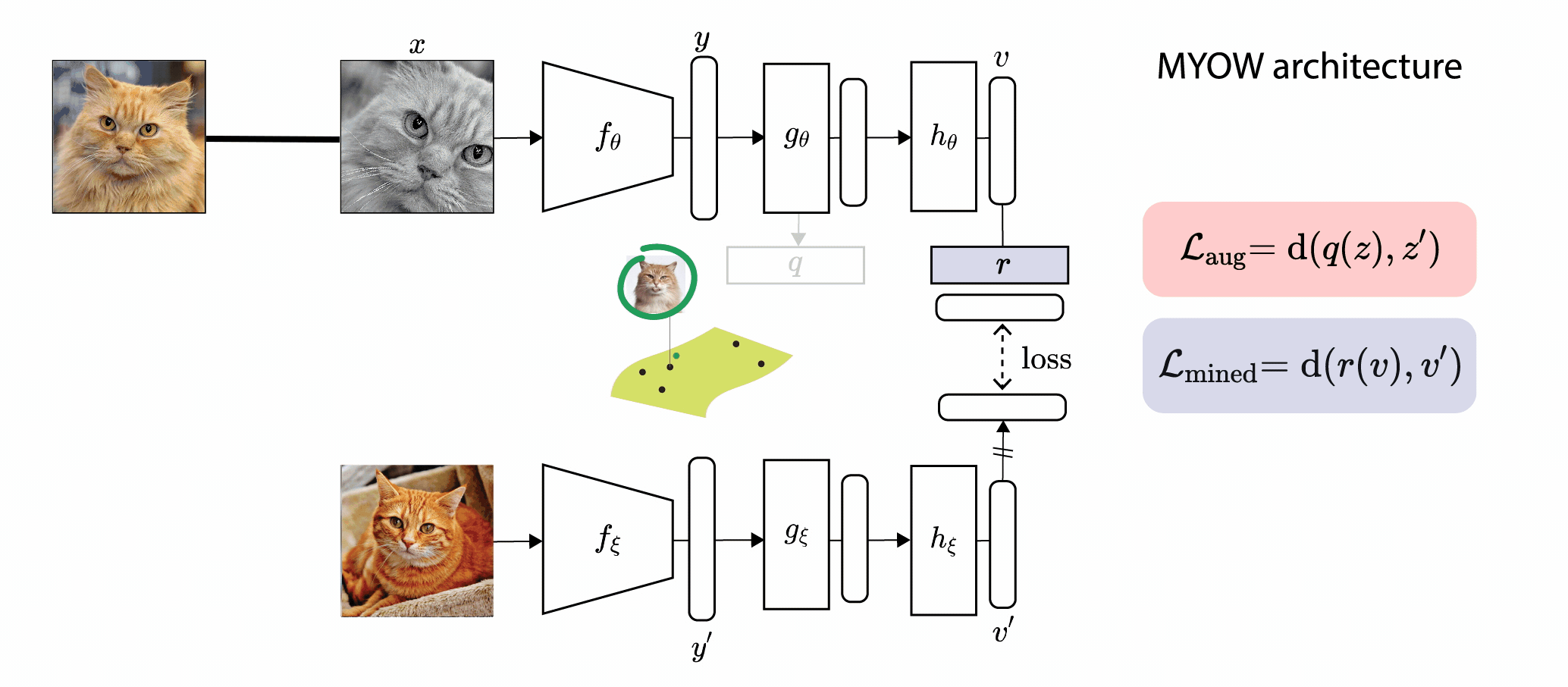
In this paper, we introduce Mine Your Own vieW (MYOW), a new approach for self-supervised
learning that looks within the dataset to define diverse targets for prediction. The idea behind our approach is
to actively mine views, finding samples that are neighbors in the representation space of the network, and then
predict, from one sample's latent representation, the representation of a nearby sample. After showing the promise
of MYOW on benchmarks used in computer vision, we highlight the power of this idea in a novel application in
neuroscience where SSL has yet to be applied. When tested on multi-unit neural recordings, we find that MYOW
outperforms other self-supervised approaches in all examples (in some cases by more than 10%), and often surpasses
the supervised baseline. With MYOW, we show that it is possible to harness the diversity of the data to build rich
views and leverage self-supervision in new domains where augmentations are limited or unknown.